When performing batch processing in Azure Databricks, you need to know the terms workflows and jobs. When you are in the Azure Databrick workspace and select Workflows from the navigation menu and then click the Create Job button, a window like the one illustrated in Figure 6.16 is rendered. The options available in the Type drop‐down are Notebook, Jar, and Python.
Once the job is created, you can schedule to run it at given time intervals, as you would expect. Notice in Figure 6.16 the cluster named Shared_job_cluster, which will be used for compute power to run your jobs. Azure Databricks offers two kinds of clusters. The aforementioned cluster, which will run your jobs, is a job cluster, also called an automated cluster. As the name implies, automated clusters are recommended for scheduled computerized jobs. When the Azure Databricks job scheduler is triggered, it will configure and provision a new job cluster to run your job on. The scheduler will also decommission the job cluster when the job is completed. The other type of cluster is referred to as interactive. When you create a notebook, this is the kind of cluster you choose. An interactive cluster is most useful for development and testing. This architectural division of concerns is similar to the one discussed in the last section, in that it is important to perform collaborative development and testing on interactive clusters and perform your production batch operations on automated clusters.
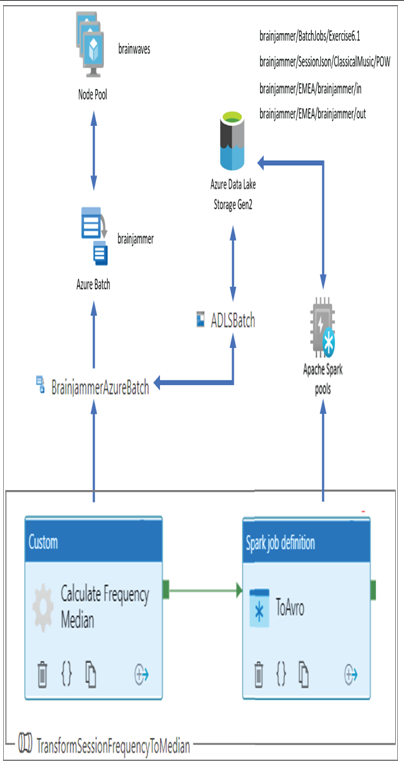
FIGURE 6.15 Azure Batch—Azure Synapse Analytics batch service pipeline with Apache Spark job definition
As stated, it is possible and often the case that your batch processing solution runs totally within the realm of Azure Databricks. It has all the features and capabilities one would expect for creating and managing an enterprise‐level batch processing solution. However, this may not always be the case in every scenario. Consider Exercise 6.4, where you will add a Notebook activity to an Azure Synapse Analytics pipeline, which will trigger the batch job running in Azure Databricks. There is no specific reason to perform this action in this scenario. All the capabilities to perform what is required exist in both of these products. The point you might take away from this is that you can mix and match, share and transfer data between all these systems, and use the best features available within them, as required. If there were ever a scenario where the Apache Spark version required to perform your task only currently existed on Azure Databricks and not on Azure Synapse Analytics, then you would have an option to progress your work forward. In many scenarios developers and data engineers have a very aggressive timeline to complete a project, so knowing more viable options can help them meet the deadline. Complete Exercise 6.4, where you will make the configurations required to run code on an Azure Databricks Apache Spark cluster, but the activity is triggered from an Azure Synapse Analytics pipeline.
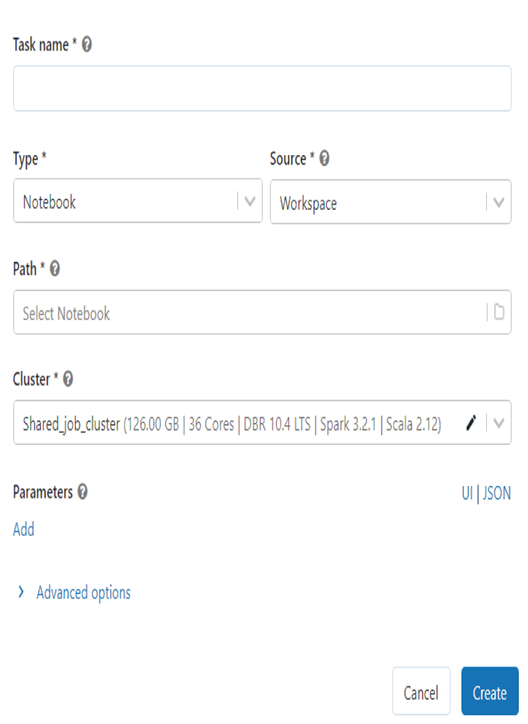
FIGURE 6.16 Azure Databricks batch job