- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the ADLS container you created in Exercise 3.1 ➢ create a directory named ToAvro in the BatchJobs directory ➢ download the ToAvro.py file from the Chapter06/Ch06Ex03 directory on GitHub ➢ place the ToAvro.py file into the BatchJobs/ToAvro directory.
- Navigate to the Azure Synapse Analytics workspace you created in Exercise 3.3 ➢ select the Open link in the Open Synapse Studio tile on the Overview blade ➢ select the Manage hub ➢ select Apache Spark pools ➢ click the + New button ➢ create a new Apache Spark pool (for example, SparkPoolBatch).
- Navigate to the Develop hub ➢ click the + to the right of Develop ➢ select Apache Spark Job Definition from the pop‐up menu ➢ select PySpark (Python) from the Language drop‐down ➢ rename the job (I used To Avro) ➢ and then add the following to the Main Definition File text box:
abfss://@.dfs.core.windows.net/BatchJobs/ToAvro/ToAvro.py - Add the following to the Command Line Arguments text box (manually update the second argument with the path to the JSON files created in Exercise 6.2):
ClassicalMusic EMEA/brainjammer/in/2022/06/15/08 @ - Click the Commit button, and then click the Publish button. The configuration should resemble Figure 6.12.
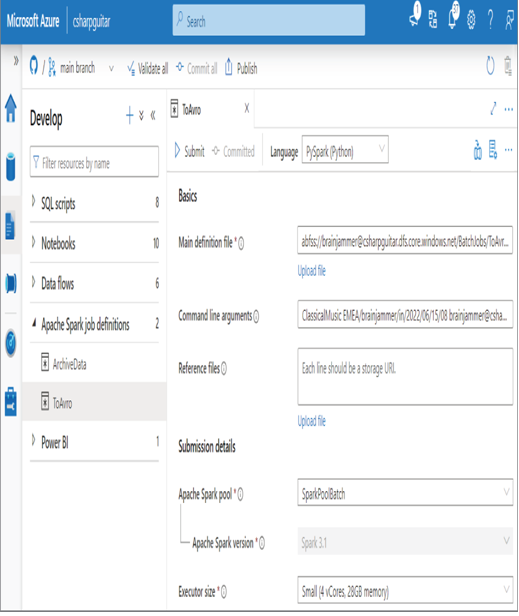
FIGURE 6.12 Azure Synapse Analytics—Apache Spark job definition
- Click the Submit button. Once complete, navigate to the directory where the AVRO files are written to view the results. The following is an example directory path:
/EMEA/brainjammer/out/YYYY/MM/DD/HH - Click the pipeline icon on the right side of the blade ➢ select Existing Pipeline ➢ select the pipeline created in Exercise 6.2 (for example, TransformSessionFrequencyToMedian) ➢ click the Add button ➢ connect the two activities by dragging the green box connector from the Calculate Frequency Median activity to the To Arvo activity ➢ select the Spark Job Definition activity in the editor canvas ➢ select the Settings tab ➢ enter the same value into the Main Definition File text box as from step 3 ➢ click the + New button to the right of Command Line Arguments ➢ enter the first argument ➢ click the + New button ➢ enter the second argument ➢ repeat the same steps for the third argument ➢ select the Apache Spark pool from the drop‐down (for example, SparkPoolBatch) ➢ select Small from the Executor Size drop‐down ➢ click the Disabled radio button to set the dynamically allocate executors ➢ enter 1 in the Executors text box ➢ click Commit ➢ click Publish ➢ and then click Debug. The output after successfully running all scenarios is shown in Figure 6.13.

FIGURE 6.13 Azure Synapse Analytics—Apache Spark job scenario result
In Exercise 6.3 you created a new Apache Spark pool (SparkPoolBatch) that is dedicated to running this job. The decision to provision a new Apache Spark pool versus running on the same as the one which has been selected to run notebooks, for example, was made for two simple reasons. The first reason has to do with the potential for the overconsumption of resources. If all the compute resources in a pool get consumed, then performance will become latent. In a scenario where you are working in a team and numerous people are testing at the same time, you may experience performance contention between team members trying to do their work. Second, from a usage and architecture management perspective, it makes sense to separate and organize nodes by function. In some scenarios there may be packages and configurations that are required in one functional area while not in another. It is not optimal in all scenarios to attempt to have identical configurations companywide. Especially when it comes to startup scripts that have credentials to other services, you want to isolate those to only those nodes that need it. Therefore, performance, better organization, and security are good reasons for functionally organizing your Apache Spark pools. Computer programming includes a concept called the separation of concerns (SoC), which can also be applied to architecture. SoC, in the context of architecture, as you can infer from the name, has to do with isolating the architecture elements away from those that might impact another. This is exactly what was adhered to by creating this new Apache Spark pool.
The first snippet of code in the ToAvro.py file initializes a SparkSession. It is necessary to instantiate a SparkSession when running an Apache Spark job, because the code runs inside a pyspark‐shell, which is not the identical case when running PySpark in a notebook. When you are running PySpark code using a notebook, the SparkSession is created for you. The creation of the SparkSession and any exposure to the pyspark‐shell is abstracted away from you but is available for reference. The SparkSession class provides the entry point for PySpark to access all the methods within the class. For example, in spark.read() and spark.write(), the keyword spark should look very familiar to you by now.