- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the Azure Synapse Analytics workspace you created in Exercise 3.3 ➢ on the Overview blade, click the Open link in the Open Synapse Studio tile ➢ select the Manage hub ➢ select SQL Pools from the menu list ➢ and then start the dedicated SQL pool.
- Select the Integrate hub ➢ create a new pipeline ➢ rename the pipeline (I used TransformEnrichment) ➢ expand the General group within the Activities pane ➢ drag and drop a Script activity to the canvas ➢ enter a name (I used DROP Tables) ➢ select the Settings tab ➢ select the WorkspaceDefaultSqlServer from the Linked Service drop‐down list box ➢ add your SQL pool name as the value of DBName (I used SQLPool) ➢ select the NonQuery radio button in the Script section ➢ and then enter the following into the Script multiline text box. Figure 5.39 represents the configuration.
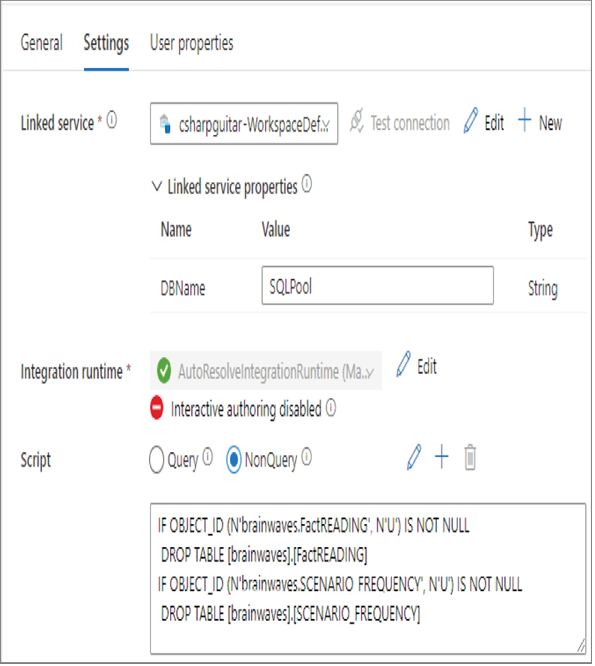
FIGURE 5.39 Transforming and enriching data—pipeline drop script
- Add a Script activity to the pipeline ➢ enter a name (I used SETUP Staging) ➢ select the WorkspaceDefaultSqlServer linked service from the drop‐down list box ➢ enter your dedicated SQL pool name as the DBName property value (I used SQLPool) ➢ select the NonQuery radio button ➢ and then add the following to the Script multiline textbox. The script is the TransformEnrichmentPipeline.txt file on GitHub, in the folder Chapter05/Ch05Ex13.
IF OBJECT_ID (N’staging.TmpREADING’, N’U’) IS NOT NULL - Click Commit ➢ click Publish ➢ click Add Trigger ➢ select Trigger Now ➢ and then click OK. Once the pipeline has completed, confirm the [staging].[TmpREADING] table exists.
- Navigate to the Develop hub ➢ create a new data flow ➢ provide a name (I used Ch05Ex13F) ➢ select the Add Source box in the canvas ➢ select Add Source ➢ enter TmpREADING as the output stream name ➢ select brainjammerSynapseTmpReading (which was created in Exercise 4.13) from the Dataset drop‐down list box ➢ click the + at the lower right of the TmpREADING source box ➢ select the Filter Row modifier ➢ enter an output stream name (I used FILTEROutliers) ➢ and then enter the following syntax into the Filter On multiline textbox:
VALUE> 0.274 || VALUE < 392 - Add a sink ➢ click the + on the lower right of the Filter transformation ➢ enter an output stream name (I used StagedTmpREADING) ➢ create a new dataset by clicking the + New button to the right of the Dataset drop‐down text box ➢ target the [staging].[TmpREADING] table you just created ➢ and then click Commit.
- Add the data flow from step 6 into your pipeline ➢ expand the Move & Transform group ➢ drag and drop a Data Flow activity to the canvas ➢ enter a name (I used FILTER Outliers) ➢ select the Settings tab ➢ select the data flow from the Data Flow drop‐down text box (for example, Ch05Ex13F) ➢ configure staging storage like you did in step 8 of Exercise 4.13 ➢ link the SETUP Staging activity to the data flow (for example, FILTER Outliers) ➢ and then click Commit. Figure 5.40 shows the configuration.
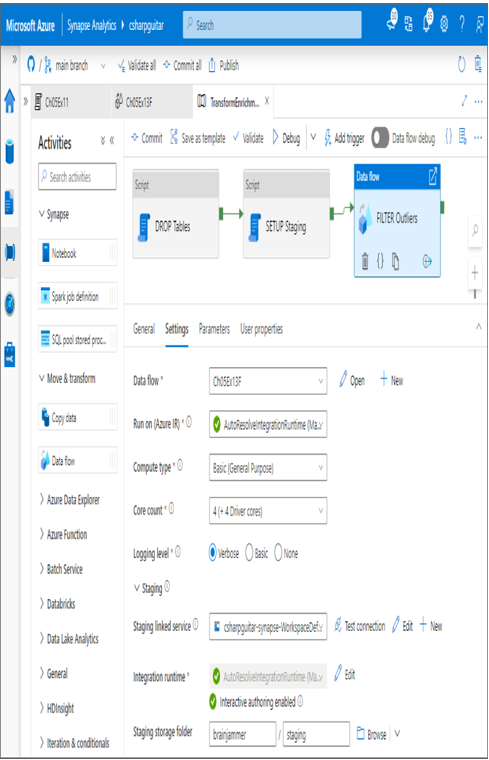
FIGURE 5.40 Transforming and enriching data —filter transformation data flow
- Add a Script activity to the pipeline ➢ enter a name (I used CREATE FactREADING) ➢ select the same linked service from the drop‐down list box as you did earlier (for example, csharpguitar‐WorkspaceDefaultSqlServer) ➢ enter your dedicated SQL pool name into the DBName property value (for example, SQLPool) ➢ select the NonQuery radio button ➢ and then add the following to the Script multiline textbox:
CREATE TABLE [brainwaves].[FactREADING] - Navigate to the Develop hub ➢ create a new notebook ➢ rename the notebook (I used Ch05Ex13TB) ➢ and then enter the following syntax:
%%spark
val df = spark.read.sqlanalytics(“SQLPool.brainwaves.FactREADING”)
- Click the Commit button ➢ add a Notebook activity to your pipeline from the Synapse group ➢ enter a name (I used CONVERT Parquet) ➢ select the Settings tab ➢ select the notebook you just created ➢ select your Spark pool (for example, SparkPool) ➢ link the CREATE FactREADING Script activity to the notebook ➢ and then click Commit.
- Add a Script activity to the pipeline ➢ enter a name (I used AGGREGATE) ➢ on the Settings tab select the same linked service from the drop‐down list box as you did earlier (for example, csharpguitar‐WorkspaceDefaultSqlServer) ➢ enter your dedicated SQL pool name into the DBName property value (I used SQLPool) ➢ select the NonQuery radio button ➢ and then add the following to the Script multiline textbox:
IF OBJECT_ID (N’brainwaves.SCENARIO_FREQUENCY’, N’U’) IS NOT NULL DROP TABLE [SCENARIO_FREQUENCY].[SCENARIO_FREQUENCY] - Link the CREATE FactREADING Script activity to the AGGREGATE Script activity ➢ click the Commit button ➢ navigate to the Develop hub ➢ create a new notebook ➢ rename the notebook (I used Ch05Ex13N) ➢ and then enter the following syntax:
%%spark
val df = spark.read.sqlanalytics(“SQLPool.brainwaves.SCENARIO_FREQUENCY”)
df.createOrReplaceTempView(“NormalizedBrainwavesSE”)